Multivariate GMM and Expectation Maximization Algorithm
Deriving the posterior, MAP and posterior predictive for the Bernoulli distribution
ML
Algorithm
Author
Haikoo Khandor
Published
May 22, 2023
Multivariate Gaussian Mixture Model
Why?
Useful when there are large datasets and it is difficult to find clusters.
More efficient than other clustering algorithms such as k-means.
# importsimport jaximport jax.numpy as jnpimport seaborn as snsimport matplotlib.pyplot as plt!pip install distraximport distraximport tensorflow_probability as tfpimport tensorflow as tf
Collecting distrax
Downloading distrax-0.1.5-py3-none-any.whl (319 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 319.7/319.7 kB 5.1 MB/s eta 0:00:00
Requirement already satisfied: absl-py>=0.9.0 in /usr/local/lib/python3.10/dist-packages (from distrax) (1.4.0)
Collecting chex>=0.1.8 (from distrax)
Downloading chex-0.1.85-py3-none-any.whl (95 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 95.1/95.1 kB 14.9 MB/s eta 0:00:00
Requirement already satisfied: jax>=0.1.55 in /usr/local/lib/python3.10/dist-packages (from distrax) (0.4.20)
Requirement already satisfied: jaxlib>=0.1.67 in /usr/local/lib/python3.10/dist-packages (from distrax) (0.4.20+cuda11.cudnn86)
Requirement already satisfied: numpy>=1.23.0 in /usr/local/lib/python3.10/dist-packages (from distrax) (1.23.5)
Requirement already satisfied: tensorflow-probability>=0.15.0 in /usr/local/lib/python3.10/dist-packages (from distrax) (0.22.0)
Requirement already satisfied: typing-extensions>=4.2.0 in /usr/local/lib/python3.10/dist-packages (from chex>=0.1.8->distrax) (4.5.0)
Collecting numpy>=1.23.0 (from distrax)
Downloading numpy-1.26.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (18.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 18.2/18.2 MB 87.4 MB/s eta 0:00:00
Requirement already satisfied: toolz>=0.9.0 in /usr/local/lib/python3.10/dist-packages (from chex>=0.1.8->distrax) (0.12.0)
Requirement already satisfied: ml-dtypes>=0.2.0 in /usr/local/lib/python3.10/dist-packages (from jax>=0.1.55->distrax) (0.2.0)
Requirement already satisfied: opt-einsum in /usr/local/lib/python3.10/dist-packages (from jax>=0.1.55->distrax) (3.3.0)
Requirement already satisfied: scipy>=1.9 in /usr/local/lib/python3.10/dist-packages (from jax>=0.1.55->distrax) (1.11.3)
Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.10/dist-packages (from tensorflow-probability>=0.15.0->distrax) (1.16.0)
Requirement already satisfied: decorator in /usr/local/lib/python3.10/dist-packages (from tensorflow-probability>=0.15.0->distrax) (4.4.2)
Requirement already satisfied: cloudpickle>=1.3 in /usr/local/lib/python3.10/dist-packages (from tensorflow-probability>=0.15.0->distrax) (2.2.1)
Requirement already satisfied: gast>=0.3.2 in /usr/local/lib/python3.10/dist-packages (from tensorflow-probability>=0.15.0->distrax) (0.5.4)
Requirement already satisfied: dm-tree in /usr/local/lib/python3.10/dist-packages (from tensorflow-probability>=0.15.0->distrax) (0.1.8)
Installing collected packages: numpy, chex, distrax
Attempting uninstall: numpy
Found existing installation: numpy 1.23.5
Uninstalling numpy-1.23.5:
Successfully uninstalled numpy-1.23.5
Attempting uninstall: chex
Found existing installation: chex 0.1.7
Uninstalling chex-0.1.7:
Successfully uninstalled chex-0.1.7
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
lida 0.0.10 requires fastapi, which is not installed.
lida 0.0.10 requires kaleido, which is not installed.
lida 0.0.10 requires python-multipart, which is not installed.
lida 0.0.10 requires uvicorn, which is not installed.
cupy-cuda11x 11.0.0 requires numpy<1.26,>=1.20, but you have numpy 1.26.2 which is incompatible.
Successfully installed chex-0.1.85 distrax-0.1.5 numpy-1.26.2
\[\begin{equation}
P_{1}(X) \ and\ P_{2}(X)
\end{equation}\] both integrate to 1 so if we add these two we will get a distribution which integrates to 2!
This violates the normalization constraint that the integral of a PDF must be 1 over all domain.
Solution?
Introduce some weighting coefficients in front of the two distributions such that the normalization is not violated. Thus,
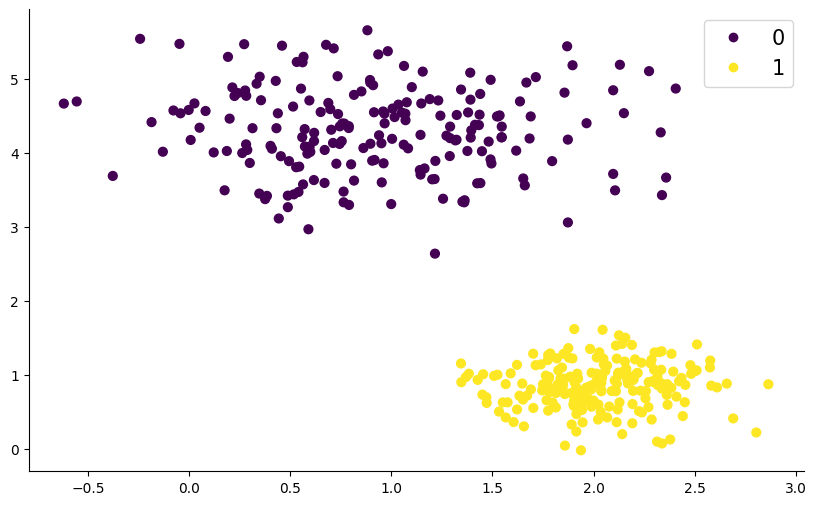
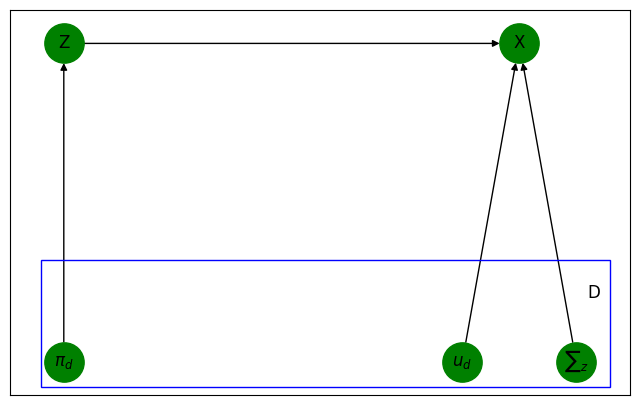
We don’t know to which cluster does a point belong to. We are interested in finding out the same. Hence this is a latent information i.e. the information we don’t observe. Thus \(P(X)\) is a marginal PDF.
Now let us model the clusters as \(Z = {0,......D-1}\), which makes it easy for us to perform cluster assignment. Thus the set \(Z\) determines the position \(X\).
Remember! We don’t observe \(Z\), i.e. we do not know to which cluster does \(X\) belong to.