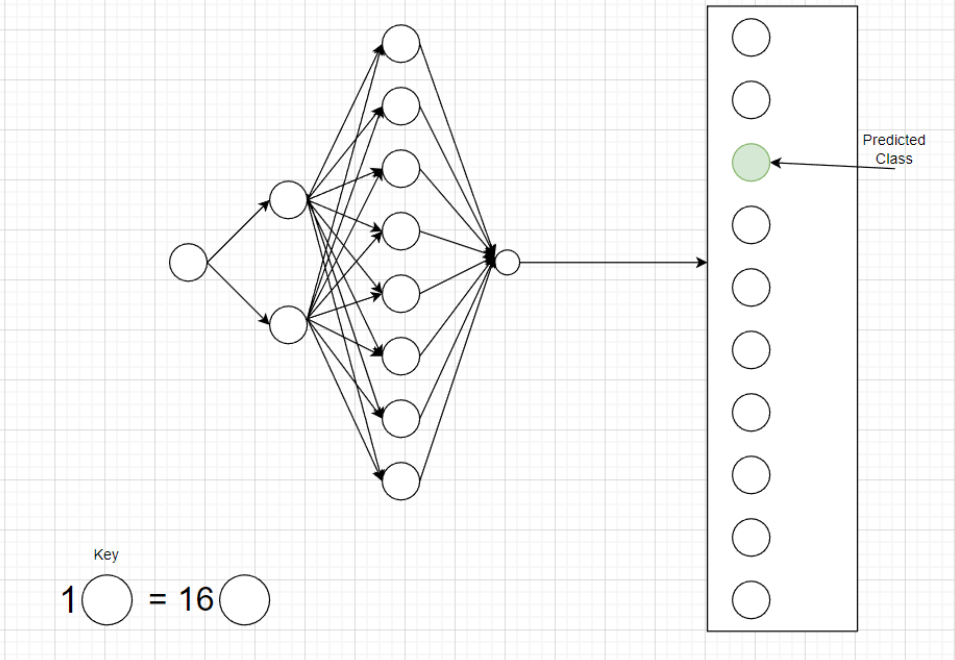
class CNN(nn.Module):@nn.compactdef__call__(self, x, deterministic: bool=True): x = nn.Conv(features=32, kernel_size=(3, 3))(x) x = nn.relu(x) x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2)) x = nn.Conv(features=64, kernel_size=(3, 3))(x) x = nn.relu(x) x = nn.Dropout(0.3, deterministic=deterministic)(x) x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2)) x = x.reshape((x.shape[0], -1)) x = nn.Dense(features=256)(x) x = nn.relu(x) x = nn.Dense(features=10)(x)return x
# Loss function for multi-class classification = cross-entropy lossdef cross_entropy_loss(*, logits, labels):# one-hot encoding for cross entropy loss labels_onehot = jax.nn.one_hot(labels, num_classes=10)return optax.softmax_cross_entropy(logits=logits, labels=labels_onehot).mean()
# compute-metrics for returning the loss and accuracy of the modeldef compute_metrics(*, logits, labels): loss = cross_entropy_loss(logits=logits, labels=labels) accuracy = jnp.mean(jnp.argmax(logits, -1) == labels) metrics = {'loss': loss,'accuracy': accuracy, }return metrics
@jax.jitdef train_step(state, batch):def loss_fn(params, rngs): # training for a single step logits = CNN().apply({'params': params}, batch['image'], deterministic=True, rngs=rngs) loss = cross_entropy_loss(logits=logits, labels=batch['label'])return loss, logits grad_fn = jax.value_and_grad(loss_fn, has_aux=True) (_, logits), grads = grad_fn(state.params, rngs={'dropout': jax.random.PRNGKey(0)}) state = state.apply_gradients(grads=grads) metrics = compute_metrics(logits=logits, labels=batch['label'])return state, metrics
@jax.jit# gives the loss and accuracy of the model on the test imagesdef eval_step(params, batch): logits = CNN().apply({'params': params}, batch['image'], deterministic=True, rngs={'dropout': jax.random.PRNGKey(0)})return compute_metrics(logits=logits, labels=batch['label']), logits
def train_epoch(state, train_ds, batch_size, epoch, rng): # Train for a single epoch train_size =len(train_ds['image']) steps_per_epoch = train_size // batch_size perms = jax.random.permutation(rng, train_size)# in case of incomplete batch since no. of training points might not be a clear multiple of the batch size perms = perms[:steps_per_epoch * batch_size] perms = perms.reshape((steps_per_epoch, batch_size)) batch_metrics = []for perm in perms: batch = {k: v[perm, ...] for k, v in train_ds.items()} state, metrics = train_step(state, batch) batch_metrics.append(metrics) batch_metrics_np = jax.device_get(batch_metrics) epoch_metrics_np = { k: np.mean([metrics[k] for metrics in batch_metrics_np])for k in batch_metrics_np[0]}print('train epoch: %d, loss: %.4f, accuracy: %.2f'% (epoch, epoch_metrics_np['loss'], epoch_metrics_np['accuracy'] *100))return state
state = create_train_state(init_rng, learning_rate, momentum)del init_rng # Must not be used anymore.
num_epochs =10batch_size =32
import jaximport jax.numpy as jnp
We iterate through the original dataset which is in the form of a dictionary with the keys as images and labels respectively. Then by running a simple for loop, we add the images and the corresponding labels to the \(x\) and \(y\) arrays. Since we need \(500\) images of each class, we stop if the count of the images left to be added becomes zero. After the loop, \(500\) images of each class has been added to the two arrays for training and further evaluation.
We can see that in the first training epoch, the accuracy on train and test are good but not upto the level. As the training goes on, the accuracy improves for both the instances. Also the accuracy does not immediately go to \(100\%\) which might become a measure of overfitting if it did so. But here that is not the case.
b = nn.softmax(logits_tot[9][-11])
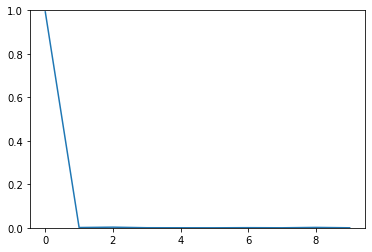
import matplotlib.pyplot as pltdigits = np.arange(10)plt.plot(digits, b)
import matplotlib.pyplot as pltplt.imshow(test_ds_new_fashion['image'][1].reshape(28, 28))
<matplotlib.image.AxesImage at 0x7f4ca5e07750>
b = logits[1]
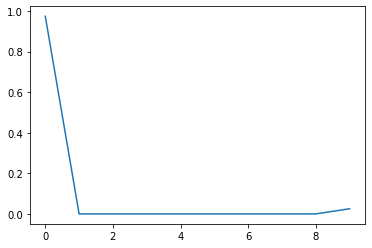
import matplotlib.pyplot as pltdigits = np.arange(10)plt.plot(digits, b)plt.ylim(0, 1)
(0.0, 1.0)
test_ds_new_fashion['label'][1]
4.0
\(99.1\%\) probability! The model is absolutely certain that the image is some digit. This is a big disadvantage of neural networks. Hence we need to incorporate the concept of uncertainty to show us how the much is the model unceratain about its predictions. We use MC Dropout for the next question to show this.
Neural Network with MC Dropout
!pip install -q flax
# necessary importsimport jaximport jax.numpy as jnpfrom flax import linen as nnfrom flax.training import train_stateimport numpy as npimport optaximport tensorflow_datasets as tfds
class CNN(nn.Module):@nn.compactdef__call__(self, x, deterministic: bool=True): x = nn.Conv(features=32, kernel_size=(3, 3))(x) x = nn.relu(x) x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2)) x = nn.Conv(features=64, kernel_size=(3, 3))(x) x = nn.relu(x) x = nn.Dropout(0.3, deterministic=deterministic)(x) x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2)) x = x.reshape((x.shape[0], -1)) x = nn.Dense(features=256)(x) x = nn.relu(x) x = nn.Dropout(0.3, deterministic=deterministic)(x) x = nn.Dense(features=10)(x)return x
# Loss function for multi-class classification = cross-entropy lossdef cross_entropy_loss(*, logits, labels):# one-hot encoding for cross entropy loss labels_onehot = jax.nn.one_hot(labels, num_classes=10)return optax.softmax_cross_entropy(logits=logits, labels=labels_onehot).mean()
# compute-metrics for returning the loss and accuracy of the modeldef compute_metrics(*, logits, labels): loss = cross_entropy_loss(logits=logits, labels=labels) accuracy = jnp.mean(jnp.argmax(logits, -1) == labels) metrics = {'loss': loss,'accuracy': accuracy, }return metrics
@jax.jitdef train_step(state, batch):def loss_fn(params, rngs): # training for a single step logits = CNN().apply({'params': params}, batch['image'], deterministic=False, rngs=rngs) loss = cross_entropy_loss(logits=logits, labels=batch['label'])return loss, logits grad_fn = jax.value_and_grad(loss_fn, has_aux=True) (_, logits), grads = grad_fn(state.params, rngs={'dropout': jax.random.PRNGKey(0)}) state = state.apply_gradients(grads=grads) metrics = compute_metrics(logits=logits, labels=batch['label'])return state, metrics
@jax.jit# gives the loss and accuracy of the model on the test imagesdef eval_step(params, batch): logits = CNN().apply({'params': params}, batch['image'], deterministic=False, rngs={'dropout': jax.random.PRNGKey(0)})return compute_metrics(logits=logits, labels=batch['label']), logits
def train_epoch(state, train_ds, batch_size, epoch, rng): # Train for a single epoch train_size =len(train_ds['image']) steps_per_epoch = train_size // batch_size perms = jax.random.permutation(rng, train_size)# in case of incomplete batch since no. of training points might not be a clear multiple of the batch size perms = perms[:steps_per_epoch * batch_size] perms = perms.reshape((steps_per_epoch, batch_size)) batch_metrics = []for perm in perms: batch = {k: v[perm, ...] for k, v in train_ds.items()} state, metrics = train_step(state, batch) batch_metrics.append(metrics) batch_metrics_np = jax.device_get(batch_metrics) epoch_metrics_np = { k: np.mean([metrics[k] for metrics in batch_metrics_np])for k in batch_metrics_np[0]}print('train epoch: %d, loss: %.4f, accuracy: %.2f'% (epoch, epoch_metrics_np['loss'], epoch_metrics_np['accuracy'] *100))return state
state = create_train_state(init_rng, learning_rate, momentum)del init_rng # Must not be used anymore.
num_epochs =10batch_size =32
import jaximport jax.numpy as jnp
We iterate through the original dataset which is in the form of a dictionary with the keys as images and labels respectively. Then by running a simple for loop, we add the images and the corresponding labels to the \(x\) and \(y\) arrays. Since we need 500 images of each class, we stop if the count of the images left to be added becomes zero. After the loop, \(500\) images of each class has been added to the two arrays for training and further evaluation.
We can see that in the first training epoch, the accuracy on train and test are good but not upto the level. As the training goes on, the accuracy improves for both the instances. Also the accuracy does not immediately go to \(100\%\) which might become a measure of overfitting if it did so. But here that is not the case.
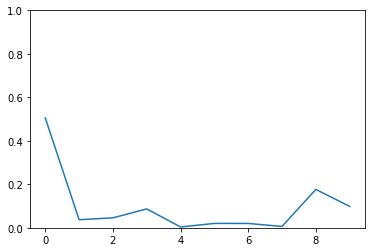
b = nn.softmax(logits_tot[9][-11])
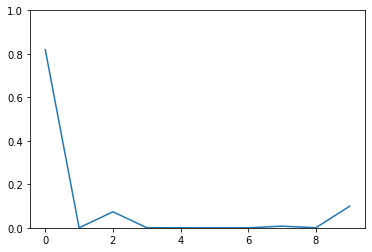
import matplotlib.pyplot as pltdigits = np.arange(10)plt.plot(digits, b)plt.ylim(0, 1)
\(50\%\) probability! The model is now uncertain about its prediction. This is a big advantage of MC Dropout. Here we have incorporated the concept of uncertainty to show us how the much is the model unceratain about its predictions. Although the prediction is wrong, \(50\%\) probability shows that it is uncertain.